
The AI (artificial intelligence, data science & machine learning) team here at Iterable strives to deliver high-quality, updated machine learning models to our customers. However, even if we’ve made a great model, how can we decide before deployment that this model is good enough to deploy? How can we avoid deploying “bad” models (models which don’t reflect our customers’ data well or have mistakes or biases in their design)? How can we automate such testing to fit within our CI/CD framework?
In this article, I will outline the types of models used by our team and the challenges in testing them, followed by a description of our end-to-end “synthetic data” testing solution for Send Time Optimization, one of our team’s products.
Unsupervised Machine Learning
Why Use Unsupervised ML?
The types of machine learning models we use are entirely motivated by the types of data available to us. The vast majority of Iterable’s data does not contain a “ground truth” label—for example, is there a “ground truth” best time to send an email to a given customer, and even if there is, how could we identify that “ground truth” and validate the “ground truth” label for accuracy? This means that supervised ML methods can’t be applied here, as we cannot define a loss function to optimize. Instead, we must use unsupervised ML algorithms to extract insights from our vast quantities of data.
Measuring Performance of Unsupervised ML Models
The AI team monitors the performance of our production models “in the wild” through key performance indicators (KPIs) such as open rate lift (please download “The Growth Marketer’s Guide to Email Metrics” for more information about these metrics!). Although KPIs are a great tool, the goal for this project is to identify problems before the model makes it into production, instead of afterwards. Therefore, I’ll focus on tests I can perform immediately after training, not tests in production.
One of the challenges in working with unsupervised models is evaluating their performance — since you don’t have a “ground truth” for comparison, it’s not always obvious how to judge your model’s predictions or results. For example, one of the classic data science projects for exploring NLP (natural language processing) is topic modeling on the New York Times articles dataset.
Most data scientists can easily produce a model which can output lists of words describing various “topics” within the dataset. It’s much more challenging, however, to determine if those topics reflect the data well; often the scientist will simply read the topics and decide if the topics match some internal expectations they have about what the “correct” topics should be — not a very reproducible or quantifiable test! In addition, the “human eyeballs” test is extremely susceptible to biases (the scientist might overlook clusters they can’t interpret clearly, or they might ignore or discredit clusters from topics outside of their experience).
For the AI team, however, such “eyeball” tests aren’t really possible — I cannot feasibly review millions of email opens by myself and personally determine if our models match my expectations.
It’s pretty easy to rule out the “eyeball test”, but what options do we have left? Let’s consider clustering algorithms as an example. We can evaluate the within-cluster sum-of-squares (WCSS) to determine the “spread” or inertia of our clusters; however, many clustering algorithms minimize this value by design, and our baseline for comparison would be the WCSS from previous models (not great if both models have the same biases!).
Since we don’t have any “ground truth” labels, we can’t use many of the traditional tests of cluster quality, such as homogeneity (whether all data points in a cluster have the same “ground truth” label) or completeness (whether all data points with the same “ground truth” label belong to the same cluster).
Synthesizing Data With Labels
Bootstrapping in ML
Our approach to handling this problem is to synthesize labeled data via bootstrapping. Bootstrapping is a catch-all term referring to tests or metrics which use random sampling with replacement. A popular ML use case for bootstrapping is “bagging” (i.e. “bootstrap aggregating”), a meta-algorithm most commonly used with decision forest models to improve their performance. Bagging creates a unique sample (a “bootstrap sample”) for each decision tree in the forest by randomly sampling the original dataset with replacement. Because a bagged random forest averages the results of multiple classifiers, this results in lower variance.
For our purposes, however, we’ll use bootstrapping to select data from known distributions or distributions designed by hand, labeling the points based on their source distribution.
What is Send Time Optimization?
In this example, I will focus on testing our Send Time Optimization (STO) product. For email blast campaigns, STO experiments attempt to maximize the email open rate by reviewing recipients’ historical engagement behavior (email opens). The message is sent to each recipient at the hour they’re most likely to open it (based on their previous opens). Therefore, the “ground truth” that we’re creating in our synthetic data is each recipient’s preferred time to open emails.
Bootstrapping for Sample Synthesis
Let’s say we want to create a sample of synthetic email open data where all customers are either “morning people” (i.e. their favorite time to open emails is a normal distribution centered around 9AM) or “night people” (same thing but centered around 9pm).
- To create synthetic data for a single customer, we’ll first randomly choose this user to be either a morning person or a night person. We will also choose n_user_emails, the number of unique email opens per user (chosen from a normal distribution centered on a reasonable value).
- To synthesize a user’s email opens, we randomly sample from their “source distribution”, either the morning-centered or night-centered normal distribution, repeating this sampling n_user_emails times to generate n_user_emails opens.
- Repeat this sampling procedure for as many users as desired and save the resulting table of synthetic customer email open with day/night labels to a Delta table.
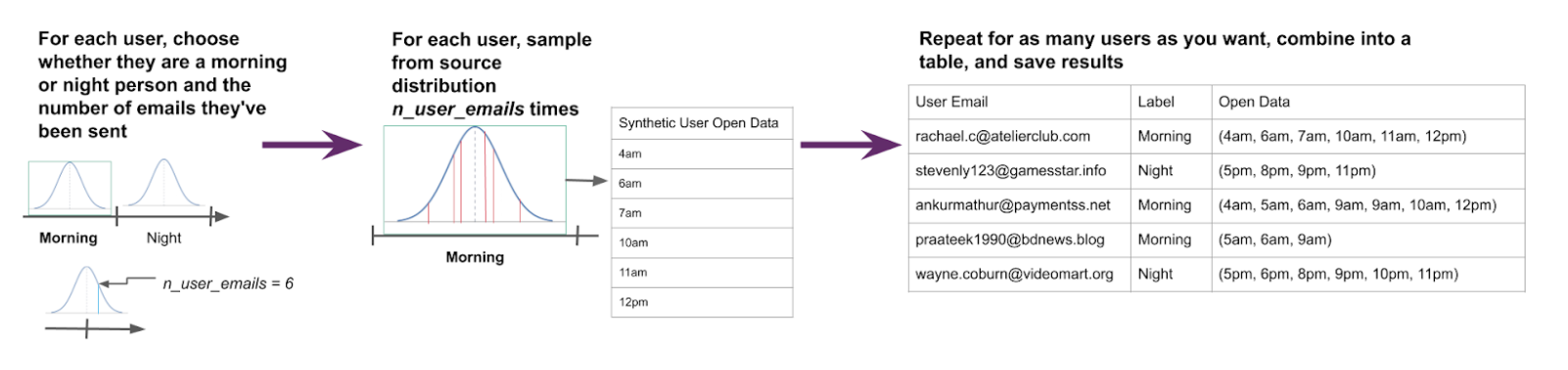
At this point, we have officially created our labeled data!
Evaluating Performance Using Synthetic Samples
Now let’s say that somebody on the AI team has made changes to the STO model and would like to confirm that the updated model performs well as part of CI/CD testing.
- When the model change is ready to merge and deploy, our CI/CD tools train a STO model reflecting the change using a recent set of synthetic data.
- Next, send a set of synthetic data (either the same as used for training, or a separate testing set) through the model API.
- The model assigns each user to a “result distribution” which should reflect that user’s open behavior, and the API samples that distribution to return the “best” open time for that particular user.
- Repeat this sampling multiple times for each user, then perform a goodness-of-fit test to determine the likelihood that these samples came from a distribution matching the user’s “source distribution” (or a very similar-looking distribution).
- If the result and source distributions have a similar shape, then the samples from the API should pass a goodness-of-fit test (such as an Anderson-Darling test) when compared to the source distribution.
- On the other hand, we might find that the results from the API were unlikely to come from a distribution matching the source (low goodness-of-fit); this could indicate that there’s an issue with our model or with the API.
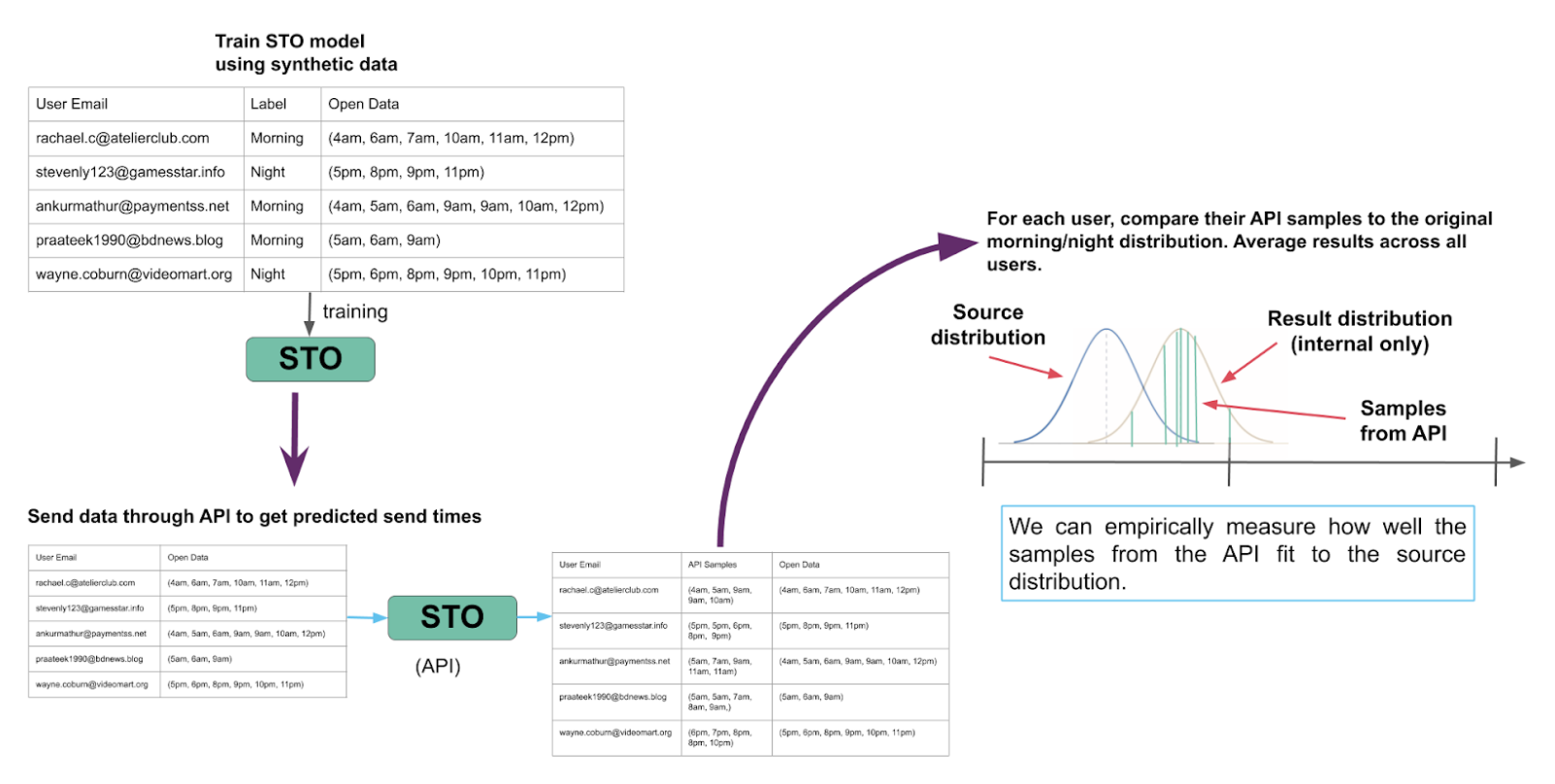
If the model’s performance meets an acceptable threshold that we define, the developer can choose to go through with deploying the model to users. Otherwise, this indicates that there’s some errors in the model and the developer should try to correct any mistakes.
Although I described a very simple testing case here (morning vs. night), this framework can be expanded to include more complex test scenarios.
Next Steps
If you’ve made it this far, thanks for reading! In this post, I summarized the reasons for synthesizing data for testing unsupervised ML models. I also gave a simple example of how you could use this test to gauge model performance in a CI/CD system.
This “end-to-end” test is an example of model testing, testing which confirms that the model follows certain expected behaviors. Adding our end-to-end test is one of several types of testing used by the AI team to ensure a high quality product. Please look for future posts from AI on ML testing and technical debt reduction; this is an active area of development for our team, and we look forward to sharing our progress with you!