Running scripts against production is a common engineering task that can be surprisingly difficult in a fully containerized environment like Kubernetes. To do it, your scripts must be placed in a container image and deployed, which requires a thorough understanding of the CI/CD environment and the creation of relevant YAML files. You’ll also need to write custom failure monitoring and restart logic. Finally, some compliance standards require an audit log for any changes to production—and completely disallow changes made from local environments.
In this post, we introduce a framework that abstracts over this complexity, allowing engineers to write scripts and run them on Kubernetes without having to edit YAML files or manually build containers—making this approach something like an internal Zapier or IFTTT for your engineering team. Though the implementation is specific to Iterable, the concept can likely be applied to any company running Kubernetes.
What is Krobs?
Enter Krobs—a framework for running scripts and cron jobs on Kubernetes, whether on a schedule or just once. Krobs prevents engineers from having to execute long-running scripts on their local machines or as cron jobs on other servers, and from having to deal with YAML files and Helm charts.
With Krobs, you can just write the script, merge, and run it via Harness—Krobs handles the YAMLs, Harness configurations and monitoring framework for you. Kubernetes jobs are guaranteed to rerun until they succeed or fail a given number of times, which is something that a normal script would have to handle explicitly.
How We’re Using Krobs
The original motivation for the tool came from the desire to avoid running long-running scripts on developer laptops. These types of scripts are most used by our Platform Services team, which is responsible for maintaining and scaling our large, multi-tenant Elasticsearch clusters and data infrastructure.
These scripts perform tasks such as draining Elasticsearch nodes, running expunges on indices, and deleting data from indices. Developers ran these scripts locally, or on various EC2 hosts. The scripts could run for hours (or days!), and each of them needed monitoring and manual restarts—taking precious focus away from real engineering.
All of the tasks mentioned above now run on Krobs. Engineers on the team write scripts, deploy them with Harness, and get status updates on a Slack channel. They can basically fire and forget, unless the job fails for some unrecoverable reason. As usage of Krobs has grown, engineers have developed common libraries. We’re also using it as a replacement for custom monitoring services—for example, we use Krobs jobs (Krob for short) to monitor the state of cluster settings in Elasticsearch (a use case that doesn’t warrant a full service).
It has only been a few months since the introduction of Krobs, so usage has mostly been limited to Elasticsearch maintenance and monitoring. We also use it for running one-off scripts during incident remediation, where—for compliance reasons—we limit access in local environments. As Krobs matures, usage may spread to other engineering teams at Iterable.
How It Works
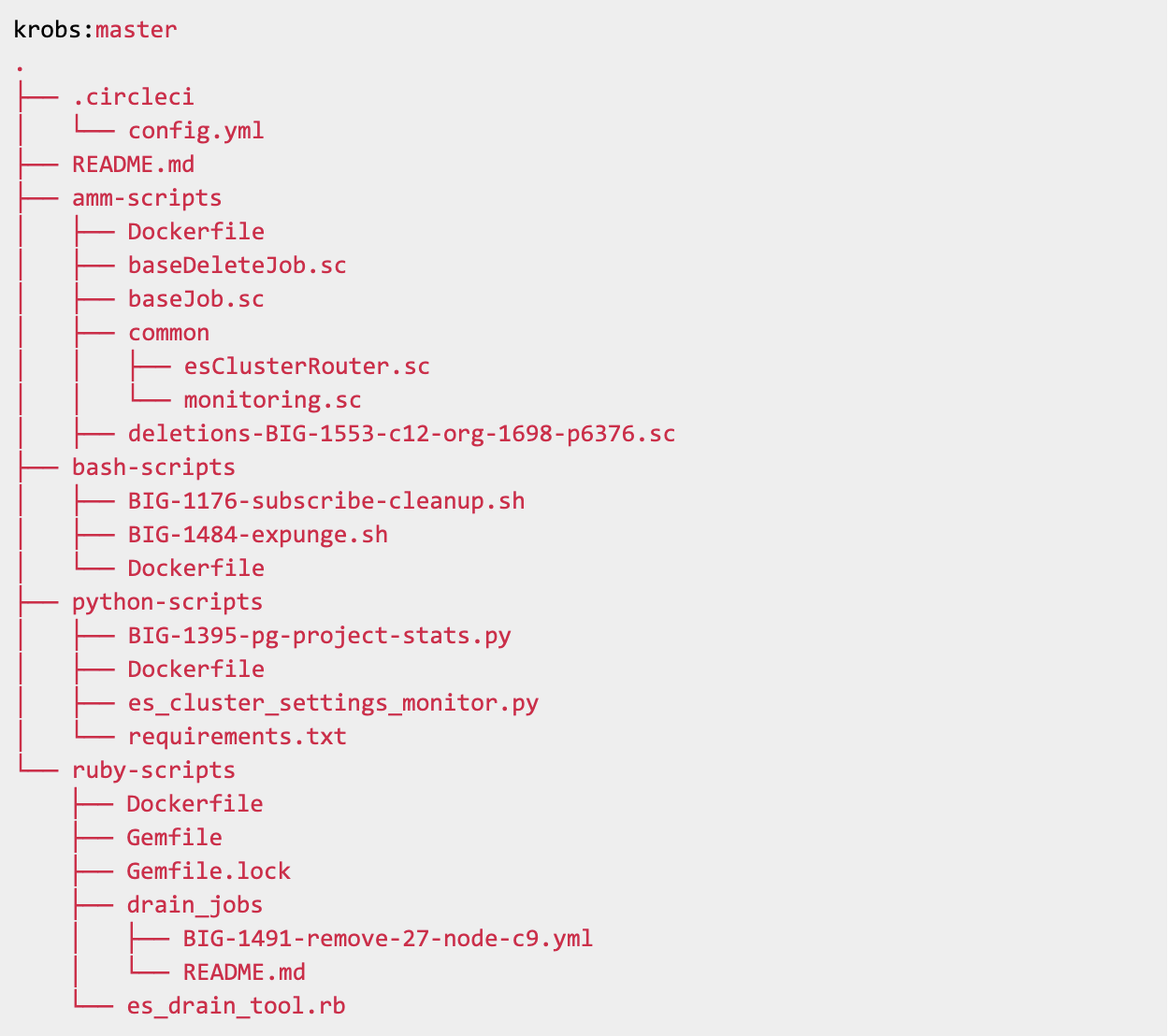
Krobs builds on the Kubernetes Job, which guarantees that one or more Pods successfully run to completion. The process of creating a Krob starts with a pull request in a dedicated Krobs repository. In this repository, there’s one folder for each programming language that Krobs supports—currently Ruby, Python, Scala (Ammonite), and Bash. Each folder contains a Dockerfile that builds the image with the given language and required packages. The Dockerfile also imports any scripts found in the folder.
The Krobs repository looks like this:
The pull request must pass review before it can be merged. This point is worth emphasizing because it’s one of the key differences between running a Krob and running ad-hoc scripts against production. The approval process ensures that at least one other engineer has reviewed the script before it runs.
After the pull request is merged, CircleCI automatically builds the images and publishes to AWS ECR. At this point, the script exists in the published container and can be run. We use Harness for CI/CD, which means we can trigger the Krob from a Harness deployment.
In the Harness deployment, we specify an environment in which to run the Krob (production or staging), a unique job name, the programming language, the name of the script, and the image that contains the given script. If the Krob is a cron job, we include a parameter to specify its cron interval.
Monitoring
Each Krob script takes advantage of existing integration with Slack and Datadog. We have a krob-monitor Kubernetes service that Krobs can POST to with Slack messages and Datadog metrics, and the monitoring service handles the details of actually posting these services. Here’s an example that shows how a Krob script might submit a Slack update from a Bash script:

Demo
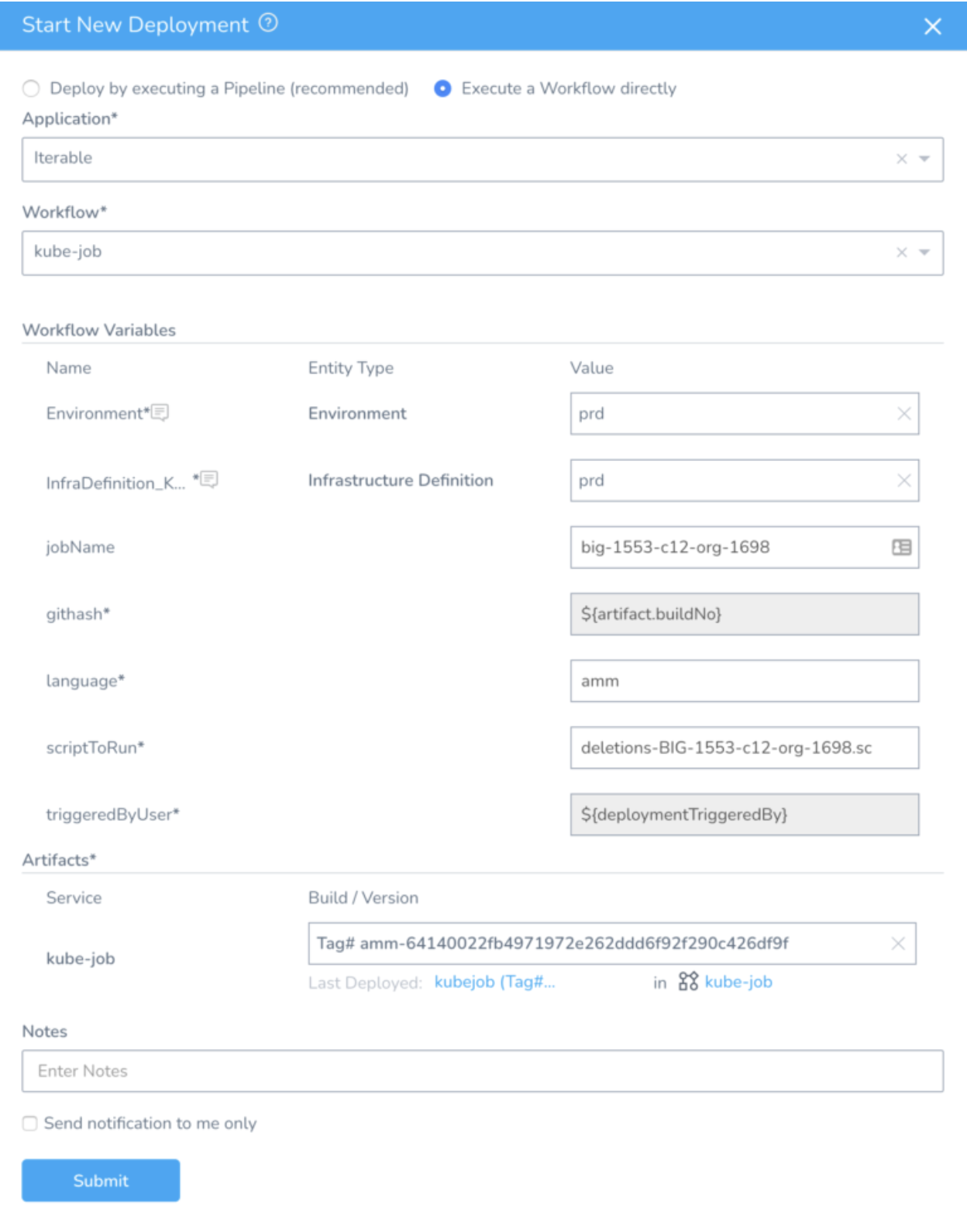
Below is an example of triggering a Krob for the script deletions-BIG-1553-c12-org-1698.sc via Harness:
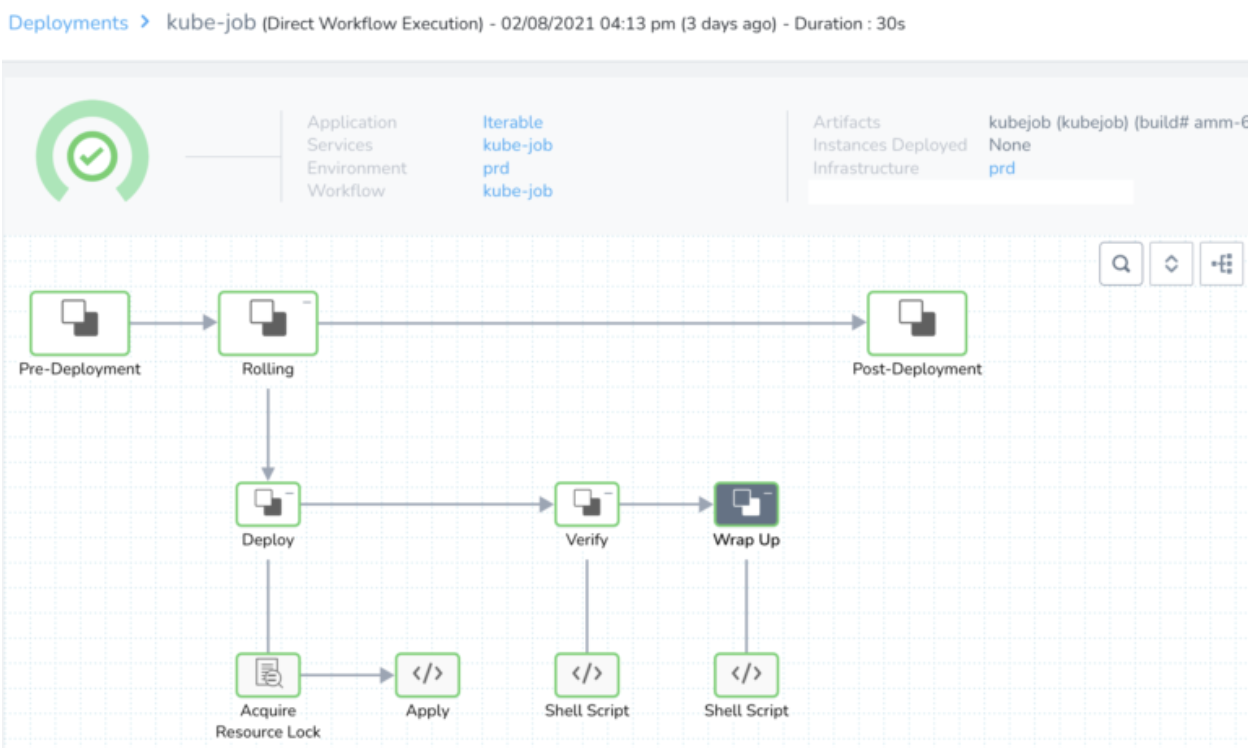
After submitting the Harness deployment, the Krob starts to run:
The job can be seen running in Kubernetes via kubectl:

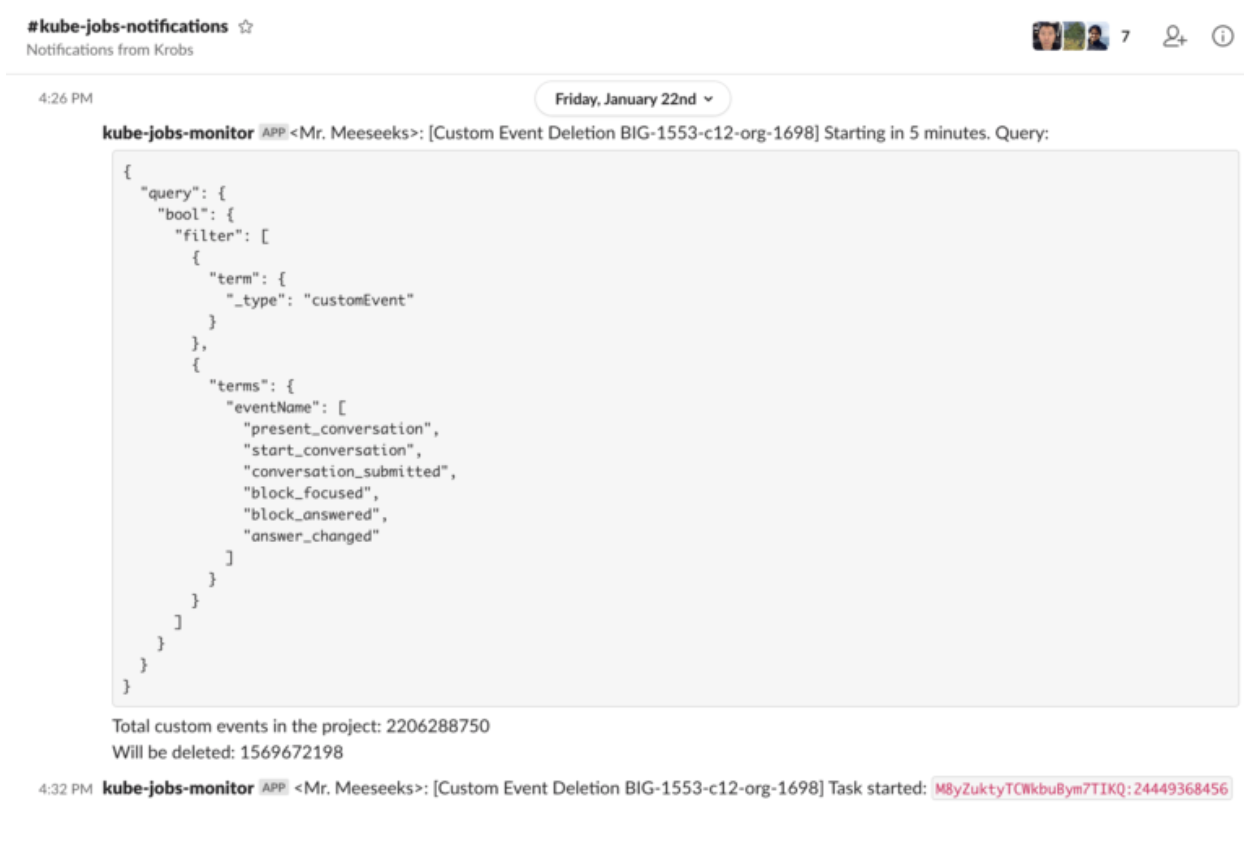
A Slack notification tells the engineer that the task has started running:
Limitations
Because Krobs is built on top of Kubernetes Jobs, there are some restrictions on the types of jobs it can run. Kubernetes Jobs must be idempotent, because Kubernetes cron jobs creates a job about once per execution time of its schedule (though they can be configured to run at least once). By extension, Krobs must also be idempotent, which may disqualify Krobs for some scripts that must be run exactly once (and can’t be made to be idempotent).
Another, we enforce a rule that Krobs shouldn’t become load-bearing posters. If a Krob fails, there should be no production impact. Krobs should never become mission-critical parts of an application (to avoid having an obscure, unmaintained Krob running a critical part of the app), and hard to identify when it inevitably breaks.
Finally, to avoid the creation of a bunch of miscellaneous scripts without known owners, each Krob should be thoroughly documented (its functionality, owner, and intended cron schedule if it is a cron job).
Conclusion
By making it easier to run scripts against production Kubernetes in a secure and auditable away, Krobs has reduced the amount of operational work required of Iterable engineers. We’ve implemented Krobs on Kubernetes Jobs and Harness, but it should be possible to build a similar tool on any stack with a Kubernetes cluster.