Iterable helps companies use data about their users and events to send more relevant and effective marketing campaigns. Iterable’s customers span many different industries and sizes, and together they send Iterable hundreds of millions of user updates and billions of events every day.
This article will describe some ways that Iterable’s architecture has improved over time to better handle various key scenarios, using Kafka and Akka Streams.
The Problem
Over the last few years, Iterable’s customer base has been growing and so has the load on the data ingestion service. This often resulted in processing delays, which significantly hindered customer experience.
Iterable ingests users and events through its API and stores them in Elasticsearch, to enable quick filtering and aggregation. When the user data is ingested, customer-defined actions may need to be triggered. For example, a “signed up” event may trigger a welcome email or an in-app message.
Iterable’s data infrastructure team defined several requirements for the ingestion service, some of which the original architecture did not fully meet:
- When a customer sends an event or an update through Iterable’s API, it must be processed as soon as possible.
- The service should be able to handle hundreds of thousands of events per second without backing up queues.
- Events and updates for the same user need to be processed in order.
- The service should be able to react to downstream delays without falling over.
- Processing speed should be limited by Elasticsearch indexing speed, not by other components.
Original Architecture
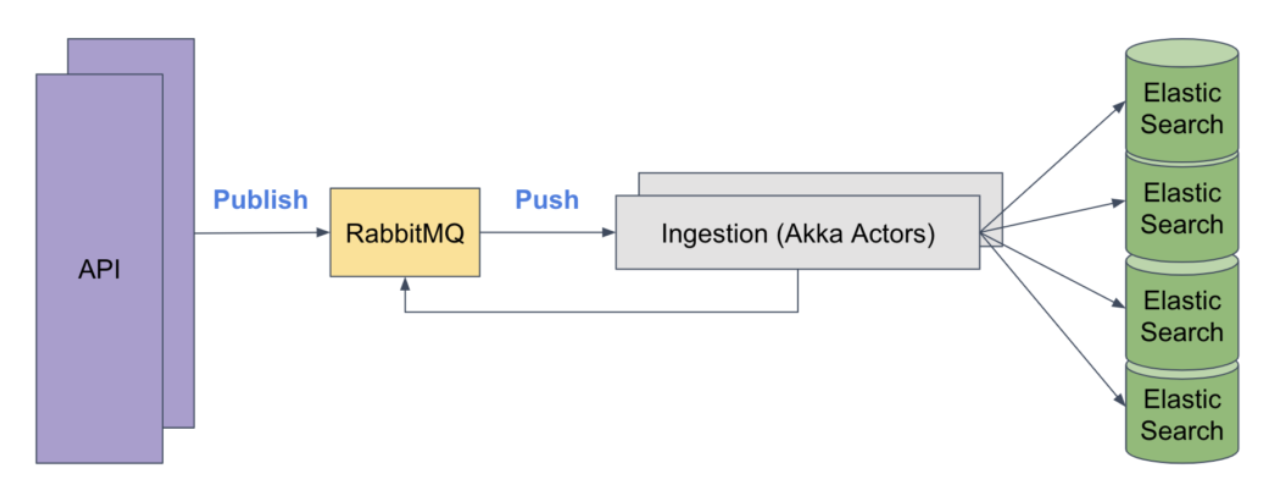
The original ingestion architecture used RabbitMQ queues to enqueue these updates, then the ingestion service used Akka Actors to receive messages from RabbitMQ and process them. This architecture had various ramifications:
- It had both a bulk and an individual endpoint on the API. For the bulk endpoint, it would enqueue in batches, breaking down to 100 messages per batch. For the individual updates, it would enqueue the updates one at at time. This allowed the ingestion service to process in batches only for the bulk endpoint, and led to a somewhat variable amount of work on the ingestion service.
- The ingestion of events can trigger other actions to happen. For example, a customer may want a “signed up” event to trigger a welcome email campaign. To handle that, the ingestion service needed to publish to another queue.
- Under high load, RabbitMQ can have issues with flow control. This means RabbitMQ blocks publishes to slow down the rate at which messages are getting published. This would happen both on the API (causing request timeouts) and within the ingestion service when publishing to other queues.
- Ingestion messages were not necessarily processed in order, which was an issue. As is typical with RabbitMQ, there was a consumer prefetch count, a number of messages RabbitMQ will leave unacknowledged on the queue. So, if the prefetch count was set to 20, the ingestion service would initially get 20 messages to be processed in parallel. A new message would be delivered each time an outstanding one was acknowledged. This meant processing could sometimes happen out of order.
- When encountering recoverable errors, the ingestion service would reject the message, which re-enqueues it. This was even worse for ordering.
Ordering Issues
Here’s a simple example to illustrate the ordering issues. Imagine the ingestion service gets a request with the following data fields:

then, shortly after, this request comes in:

It should be clear why these events should not be processed out of order. It’s relatively rare for this to happen, but it can be a serious issue when it does.
Another similar issue was that the old architecture separated users and events into different queues. So, if a customer sent an update and then an event for the same user to Iterable’s API, the event might be processed before the update. Such an event might trigger an email campaign, for example, which would then end up making use of old user profile data.
Throughput
The original ingestion service sent updates to Elasticsearch one record at a time, except when they were originally sent in bulk. Elasticsearch batch updates provide much higher throughput, but the existing service was not fully taking advantage of this feature.
This naive batching strategy resulted in much lower throughput than was theoretically possible with batched updates. A major goal of the new architecture was to batch updates as efficiently as possible.
New Architecture
In the new architecture, Iterable’s team decided to take advantages of a few specific tools and technologies:
- Apache Kafka: A distributed pub-sub system for processing streams of data. In Kafka, topics are partitioned into ordered streams of data, which are meant to be processed in order. It also supports higher availability and throughput than could reasonably be achieved on Iterable’s RabbitMQ infrastructure.
- Akka Streams: Provides high-level APIs to compose, slice, and dice data streams. Though there’s a bit of a learning curve, understanding Akka Streams can greatly simplify stream processing. It also makes it easy to batch data on size or time and propagates back pressure to prevent the overloading of downstream processing stages.
- Alpakka Kafka connector: Provides tools for interfacing with Kafka using Akka Streams. For example, the tool makes it possible to request a message source from Kafka, which abstracts the details of requesting new messages and buffering them for processing.
- Elasticsearch: A distributed search engine built on top of Lucene. This was pretty much a given, because Iterable already uses it to support fast searching, filtering, and segmentation of customer data.
Implementation
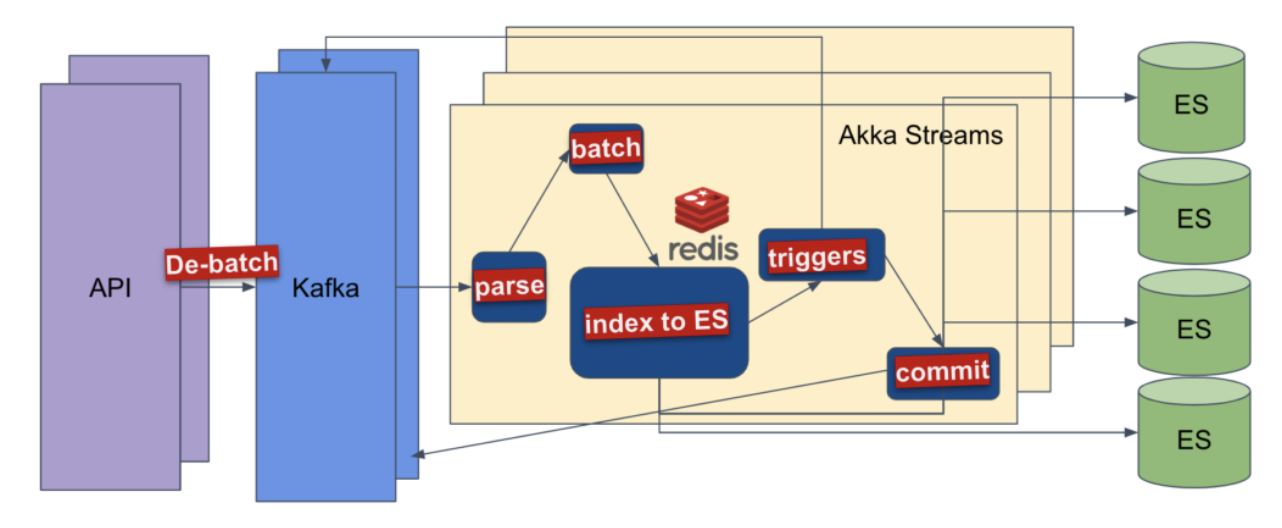
Iterable’s new ingestion architecture consists of a few parts:
- The API unbatches any already-batched messages and publishes them as individual messages. This allows the ingestion service to decide the optimal batch size after consuming. When actually transferring the messages to the Kafka broker, the Kafka client will batch them efficiently.
- The API publishes to Kafka (rather than RabbitMQ). There is a single topic for both users and events, partitioned by user ID. Partitioning by user ID achieves parallelism across many partitions while still maintaining ordering for updates to the same user. Merging user updates and events into a single topic prevents issues of inconsistent ordering between user updates and events.
- The ingestion service consumes the user updates and events from Kafka and implements a processing flow using Akka Streams. Here it groups all the incoming messages into batches that are sent as a bulk request to Elasticsearch.
- Redis is used for deduplication. Messages may be duplicated if the service needs to restart consuming from a partition after a failure, or if a message ends up being republished on the API side. This is expected because Kafka provides an “at least once” guarantee. To account for this, message IDs are stored in Redis so previously-seen messages can be discarded.
At a high level, the new ingestion service is implemented with the following processing flow:
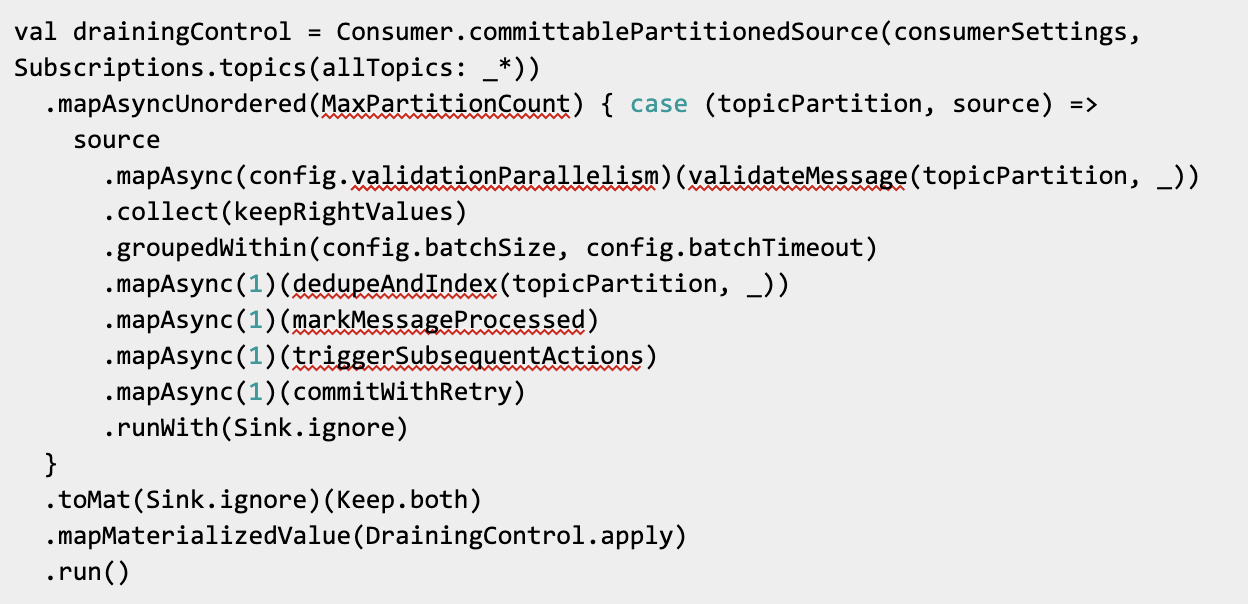
Breaking this down:

First, the service creates a source using the Alpakka connector. This helper, committablePartitionedSource, produces a source of sources. The outer source produces a Source containing CommittableMessages each time the consumer is assigned a new partition to read. That source is completed when that consumer is unassigned from that partition. Consuming each Source reads messages from the partition.

Next, mapAsyncUnordered processes each partition source. The max parallelism is equal to the maximum number of partitions that this ingestion node will process. Inside the function it eventually calls runWith(Sink.ignore) which produces a Done when the inner stream completes. That will come in handy later.
Now there’s an inner processing pipeline for the actual messages.
First, mapAsync is used to run some validation logic. This checks to make sure the organization actually exists and there are no obvious data format issues. If so, the error is reported. validateMessage actually returns an Either and the next stage keeps only the Right values.

This is asynchronous because a cache or Postgres database access may be needed, which involves I/O. Since those APIs are asynchronous and return Future instances, mapAsync is needed. parallelism > 1 can be used here since ordering does not matter, unlike some other parts of the stream.
The next stage batches all the messages that arrive within a given time, up to a given batch size:

batchSize = 5000 and batchTimeout = 250ms seems to provide good results in Iterable’s specific use case, but results can vary based on the typical size of messages.
After that, the messages are deduplicated and indexed to Elasticsearch:

This step checks the Redis duplicate tracker to see if the message exists. If it does, that means the message was already processed, perhaps because the stream died before the offset could be committed. In that case the message is skipped.
This step also merges updates for the same user within that batch into a single update. This provides significantly better performance because Elasticsearch no longer needs to force a refresh to get the current state of the user for the next update.
The next stage marks the message as processed in Redis:

Finally, the results pass through a stage that triggers any subsequent actions that should be performed.

This can send the user through a workflow that defines a series of customer-defined actions. This is the stage that would trigger the welcome email discussed above.
The last stream stage in the inner stream commits the offset to Kafka.

This is simply the commitScaladsl method call wrapped in a retry helper. The retry is necessary to handle errors due to intermittent broker outages. These outages are relatively uncommon and usually only last a few seconds in a typical case, so retrying for a few seconds is usually enough.
Note that the above stages are done with .mapAsync(parallelism = 1), meaning they process a single batch at a time. This is important for maintaining ordering.
The entire inner source is then run using Sink.ignore. This will produce a Done downstream on the outer source when consuming from that partition finishes.
The remainder of the outer graph is then wrapped in a DrainingControl:

This takes both the Done emitted by Sink.ignore when done consuming and the Control from the Kafka producer and provides a method DrainingControl#drainAndShutdown() that both triggers a shutdown and returns a Future that will be completed when the graph is shut down. This can be triggered as part of the application shutdown sequence to make sure the stream shuts down cleanly.
Handling Errors
There are a few different types of errors that might occur:
- Unrecoverable errors: These are errors with known cause but no obvious recovery plan, for example, users who are specifically banned from ingestion, or errors due to invalid data that were not caught at the API. The ingestion service simply reports the error and continues rather than trying to handle it.
- Recoverable errors: These are errors that can be retried. In the case of a 429 (Too Many Requests) or 409 (Conflict) from ElasticSearch, the failed updates can be retried with an exponential backoff. The backoff is useful in case ES is too busy to handle the amount of incoming load. Another example of a recoverable error is a Kafka commit failure due to a broker outage.
- Unknown types of errors: For unexpected exceptions the service simply allows the stream to stop, which is the default action that Akka Streams takes when it receives an exception.
The Iterable app also has a custom materializer to catch these unexpected exceptions:

This allows Iterable engineers to easily see what caused an error if the stream stops unexpectedly. When this happens, the Iterable team investigates the error and decides what to do.
Results
This new architecture resulted in a significant increase in ingestion processing speed and reliability, while achieving all the original goals. In practice, the new service achieved around 10x performance improvement with peak ingestion load, and significant processing delays were almost nonexistent.
Kafka suits Iterable’s needs much better than RabbitMQ, since it was designed to support in-order processing across many partitions. Akka Streams also suits Iterable’s needs better than (untyped) actors, because it provides a type-safe way of modeling the stream processing stages, and takes care of all the complexity of efficiently batching.
So far the Iterable team has been very happy with the investment in Akka Streams and are continually using it to improve other components of the infrastructure.