At Iterable, we want to empower our customers to include truly personalized content in marketing campaigns. Customers can now upload non-user data to Iterable Catalog and run powerful queries over them. They can build Catalog Collections using individual recipient data as parameters of the collection.
For example, a food delivery service can use Iterable’s Catalog feature to create a “new restaurants near you” Collection and send out a campaign that finds newly opened restaurants within a mile of each user’s location. Catalog Collections are completely managed by the marketer, enabling complex personalization with zero engineering resources.
The idea of storing non-user data inside Iterable is not new. Historically, such data was stored as S3 blobs, making it accessible only by ID. With Catalog, we’ve moved this data into the same Elasticsearch backend powering Iterable’s user and event segmentation. The new backend supports rich query semantics on all properties of a catalog item, including things like geolocation, star rating, product category.
Technical requirements
The technical requirements for Iterable Catalog include:
- Legacy system feature parity + data migration and conflicting data type support
- Fast small document write speeds
- Scalable fast and complex queries (up to 10s of thousands/second)
- Partial document updates
High-level Architecture
Iterable has never restricted the type of data that each customer may have in any Catalog. It’s important for us to store whatever data our customers need, whether those are restaurants, menus, product inventory, or songs, etc. The Catalog ingestion pipeline is fairly simple: requests come in through Iterable’s asynchronous API and are published to Kafka; Kafka consumers transform, batch, and index the requests into Elasticsearch (ES).
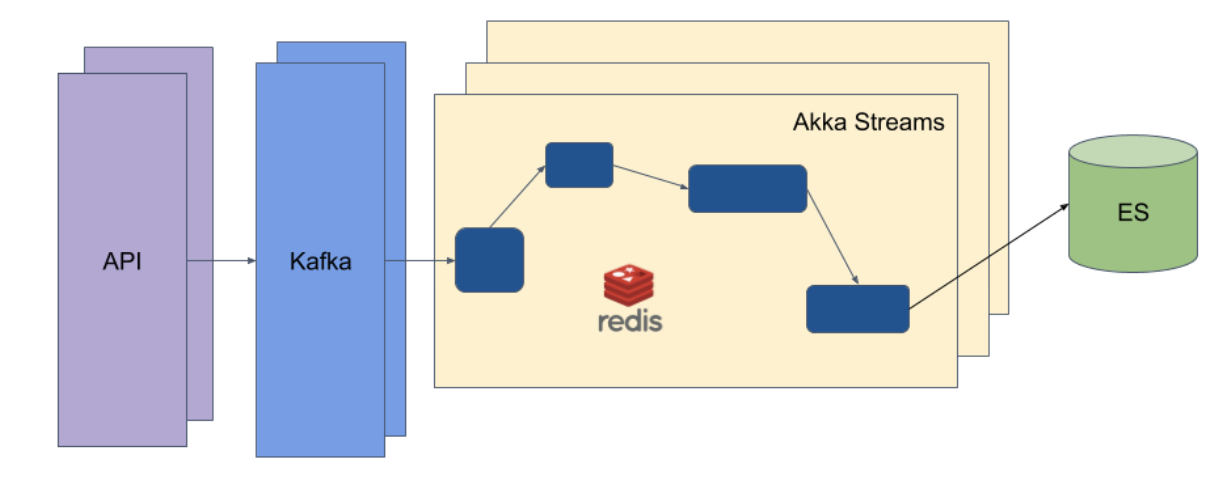
We use Kafka and Akka Streams in our ingestion service to batch updates together, for less I/O and faster writes into Elasticsearch. This was something that was never implemented in the S3 version. We also created new bulk operation endpoints at the Iterable API level to make it easier for customers to feed in more data.
Elasticsearch is a great tool for this system because it is a distributed NoSQL search engine that can perform many small, fast queries. Its indices simply store JSON documents. It also has a powerful query DSL that can provide complex and granular queries against its indices.
This has a similar shape compared to our user and event ingestion pipeline. You can read about how we optimized its performance here.
Elasticsearch Mappings and Types
In order to optimize query speed against fields in each catalog item, ES needs to know what type each field is – does it represent a number, a string, an object, a date, or location data? At index time, ES builds secondary data structures based on the type of each field, in order to perform the fast lookups at query time. The type of field also determines the class and nature of queries that can be performed against it. Elasticsearch is smart; by default, it looks at the first occurrence of a field in an index and creates a mapping for it based on the inferred type. Once it has inferred that a field is a number, future occurrences of that field must all be numbers, or the update will be dropped.
However, in the past, we have frequently seen customers make mistakes sending us data. Elasticsearch will create mappings based on these mistakes. When this happens, future “corrected” document writes may not get stored because they no longer match the original document type. Another consideration is that legacy data in S3 was never strictly typed, and does not care if a customer changes a field type. Perhaps one document has {"serialNumber": 123}, and another has {"serialNumber": "123four"}. The difference is subtle, but this state is not allowed once the documents are migrated into ES. Is serialNumber a string, or a long? It would depend on which document was indexed first. This non-deterministic behavior is obviously undesired and should be avoided.
Controlling Mappings
Automation is nice… until it isn’t. We realized that we need to prevent Elasticsearch from wrongly inferring mappings types. We want our customers, who understand their data the best, to tell us explicitly what type a field is, if and only if they want to perform queries against that field. Until they define the field mappings, they shouldn’t exist in Elasticsearch. We didn’t want to introduce a whole new source of truth database/storage system for temporary mappings data, because it is impossible to keep the external system consistent with the asynchronous, eventually consistent nature of Elasticsearch. We hoped to leverage Elasticsearch itself to store this data.
At a high level, we achieved this by breaking each document into raw and defined components, storing both inside Elasticsearch. For each catalog, we bootstrap an Elasticsearch index with dynamic templates that turns off automatic type inference for raw fields, and instead designates each as a disabled object:

Let’s break this down:
path_matchperforms a comparison against the JSON path of a field.- For Example, for
{"foo": {"bar": true}}the path ofbarisfoo.bar
- For Example, for
- Any field whose path starts with
rawwill be applied the following properties:"type": "object""enabled": false
- These two together means that any child of
rawcan have children, but ES doesn’t do anything special in terms of building supporting data structures for the field or its children, so none of the data in the field is enabled for searching. - We can still store the raw data, and at the mappings level, we have a record of all the field names that exist.
Document Transformation During Ingestion
Let’s use a concrete example to describe what happens during Catalog updates. Let’s say a customer creates a “Restaurants” catalog. Iterable will make sure the catalog has the necessary dynamic template as described above.
The customer can now send in a new catalog item update to the “Restaurants” catalog, for id uuid123:

Iterable’s Kafka consumer (the ingestion service) actually transforms the each original document by wrapping it inside a raw field and sending it to ES to store as the following:

When ES stores the transformed document, it will update mappings for the “Restaurants” catalog to include the new raw fields:

Note that even though the fields are not defined with their natural types, their existence is recorded, and any field’s data can be overwritten without affecting any other field in a subsequent partial update call.
Again, none of these fields can be searched upon at this point. They’re all children of a raw field that the customer didn’t create. However the customer can still retrieve their data by performing GET requests on the id of the restaurant. In this case, they can retrieve the data for uuid123. We would just return the contents of the raw field on the document with that id.
Because the data in each of these raw fields is an “unsearchable object”, Elasticsearch doesn’t care that the true values for these fields may have conflicting types. One can think about this concept like the Object super type in Java.
Any and all data can be upcasted, so to speak, to a “unsearchable object”. The bad state described above—one document having {"serialNumber": 123} and another having {"serialNumber": "123four"}—is fully supported. Both 123 and "123four" are “unsearchable objects.” With these simple rules and transformations, we have replicated functionality in our S3 system and can migrate all legacy data into the new database.
Allowing Customers to Explicitly Define Mappings
It’s nice to have legacy feature parity, but now we have to improve the experience. What do we do if we want customers to perform queries on their restaurants? There will obviously be more than one item in each catalog, and we want customers to search for only the items that are relevant. Recall that before allowing searching on a certain field, ES needs to know the true type of the field. It can’t be an unsearchable object.
We created both API endpoints and a user interface to allow customers to see existing defined and undefined fields, as well as define previously undefined fields. A customer can define fields that may or may not already exist on an item in the catalog. So if they’d like, they can define mappings before ingesting any data.
Keeping with the above example, let’s say the customer is now sure that location will always be a lat/lon geographical field and they want to query on that field. They can use our “update mappings” endpoint to send us a location definition for the field, and we would update the ES mappings for the catalog accordingly to look like this:

Observe that there is now a new location field that is a sibling of the raw field and it has an explicit type: geo_point. Once location is known to be of this type, all subsequent updates in the “Restaurants” catalog on the location field will trigger updates against efficient data structures for searching or aggregating against this field’s location data. So customers can perform searches like “find all restaurants whose location field is within 1 mile of a lat/lon point.”
Also note that we did not (and cannot) remove the raw.location field. Technically, all defined fields exist twice inside mappings.
Ingestion With Defined Types
Once there are explicit mappings that exist in the catalog, it is insufficient to transform the original document by simply wrapping the data inside the raw field as we’ve done previously. We also need to duplicate the defined fields’ data to match the mappings. For all defined fields, we need to extract the data in the fields. So if the user sent the uuid123 document with the same data again, our ingestion pipeline will now transform the data to look like this:

Any queries against location will be performed against the outer location field.
Caching Mappings
Those familiar with Elasticsearch may have noticed that we just introduced a new bottleneck in our ingestion pipeline. Each Kafka consumer has to perform an ES get-mappings for each catalog item update that we receive! This is a very expensive call, and can easily overwhelm Elasticsearch when performed at scale, so we wanted some kind of cache to store these mappings.
Here are some observations and requirements for the cache:
- Each Kafka consumer can index into multiple catalogs; each catalog has its own mappings
- Fields and their types in each mapping cannot be modified, but new fields can be added
- Because the customers explicitly update mappings, the cache must never serve stale mappings data
The mappings cache we built deserves a much more detailed deep dive in a future blog. This post covers only the high-level solution we implemented for the mappings cache system.
Each consumer holds an in-memory cache with a dictionary of catalog id to mappings. A separate Redis instance holds information on when each local cache needs to invalidate a Catalog entry. Before each consumer gets field type mappings for a particular Catalog, it checks Redis to see if it needs to invalidate its local cache entry for the Catalog.
Catalog Collections
At this point, we have everything we need to store our customer’s Catalog data. They can easily index and get documents as they’ve always done, but how do they actually build Collections, or subsets of their Catalogs? Our front-end team a built a powerful and beautiful UI for defining and saving Catalog Collections. Under the hood, a Catalog Collection is simply a data model representing Catalog search criteria which can be translated into an Elasticsearch query at campaign send time. It may have placeholder “dynamic” values that will be resolved by fields from a user profile.
An example Catalog Collection might be defined by the following search:
New fried chicken restaurants within 5 miles of each user.
Using the Collections builder in the UI:
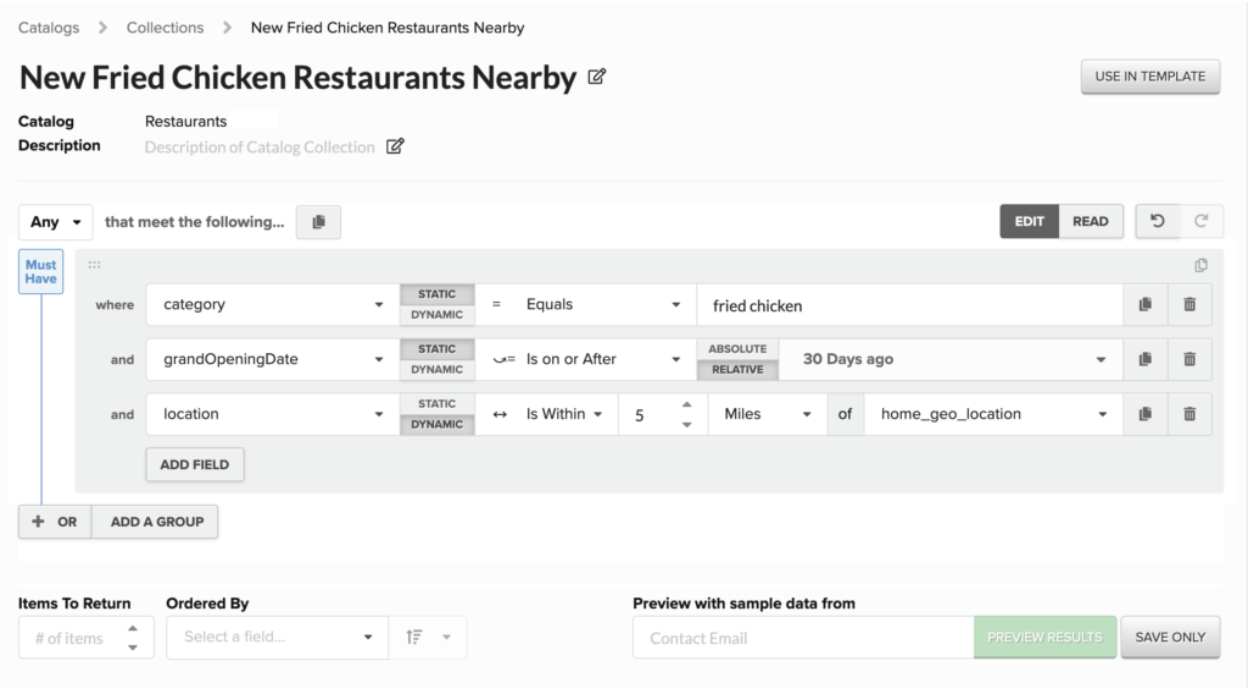
For the “Restaurants” Catalog, this translates to a pseudo-model for this might be defined as something like:

Those familiar with ES know that most of this can easily be translated into a bool query with a must query and a filter. The first element in the must query is a term or terms query against the “category” field, with fried chicken as the value. This asks if “fried chicken” appears on the category field of any document.
The second query is a date range query where the grandOpeningDate value is greater than 30 days ago. The geo_distance_range queries the location field to see if it’s within a radius of 5m of some lat/lon geo data retrieved from a recipient profile’s home_location field. If home_location on the recipient user profile resolves to {"lat": 40, "lon": -70}, the query on the index corresponding to the “Restaurants” catalog might resemble:

Results and Future
All non-users/events data inside Iterable now lives in this new Catalog system. We were able to seamlessly migrate customer data from S3 without data loss or customer interruptions. At time of writing, the Catalog feature has just been released to all customers. Since its announcement, we have seen tremendous interest to use Catalog/Catalog Collections from existing and prospective customers.
In the future, we see this turning into a fully automated content recommendation engine service that our customers can plug into. Technically, there are a few more things that we can add to our ingestion pipeline to cover corner cases that we know Elasticsearch can’t handle well. We can also add downstream publishes to feed data into Spark or some other machine learning streaming system for model training. We can add ways for customers to provide more information about each catalog so that Iterable knows how to most efficiently spread their data across Elasticsearch nodes across clusters.
Check out the feature in action at our 2019 Activate demo to see how Iterable can power personalization in growth marketing.